【UNet3+】遥感影像分割
1. 项目准备
1.1. 问题导入
-
图像分割
在计算机视觉领域,图像分割指的是将数字图像细分为多个图像子区域的过程,其目的是简化或改变图像的表示形式,使得图像更容易理解和分析。图像分割通常用于定位图像中的物体和边界,更精确的说,它是对图像中的每个像素加标签的一个过程,这一过程使得具有相同标签的像素具有某种共同视觉特性。 -
实验任务
本例简要介绍如何使用UNet3+模型实现遥感影像分割,我们需要将遥感影像中存在的建筑物分割、标注出来。
1.2. 数据集简介
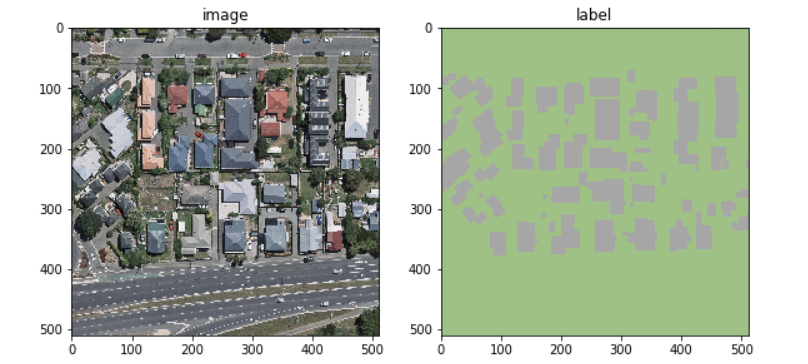
武汉大学2019年发布了Aerial Imagery Dataset,该数据集原始航拍数据来自新西兰土地信息服务网站,数据集共有8,189张具有0.3m分辨率、大小为512×512像素的遥感图像,数据集共包含18,7000座建筑物。数据集包含存放遥感图像的image文件夹和存放分割图像的label文件夹,例图如下图所示:
这是数据集的下载链接:Aerial Imagery Dataset - AI Studio
2. UNet3+模型
2.1. 背景介绍
Hinton等人(2006)提出了一种Encoder-Decoder结构,当时这个Encoder-Decoder结构提出的主要作用并不是分割,而是压缩图像和去噪声。输入是一幅图,经过下采样的编码,得到一串比原先图像更小的特征,相当于压缩,然后再经过一个解码,理想状况就是能还原到原来的图像。
后来,Jonathan等人(2015)在论文中基于该拓扑结构提出了FCN(Fully Convolutional Networks)。自提出以后,FCN就成为了语义分割的基本框架,后续算法(如UNet)其实都是在这个框架中改进而来。其中的UNet由于其对称结构简单易懂,且模型效果优秀,于是就成为了许多网络改进的范本之一。
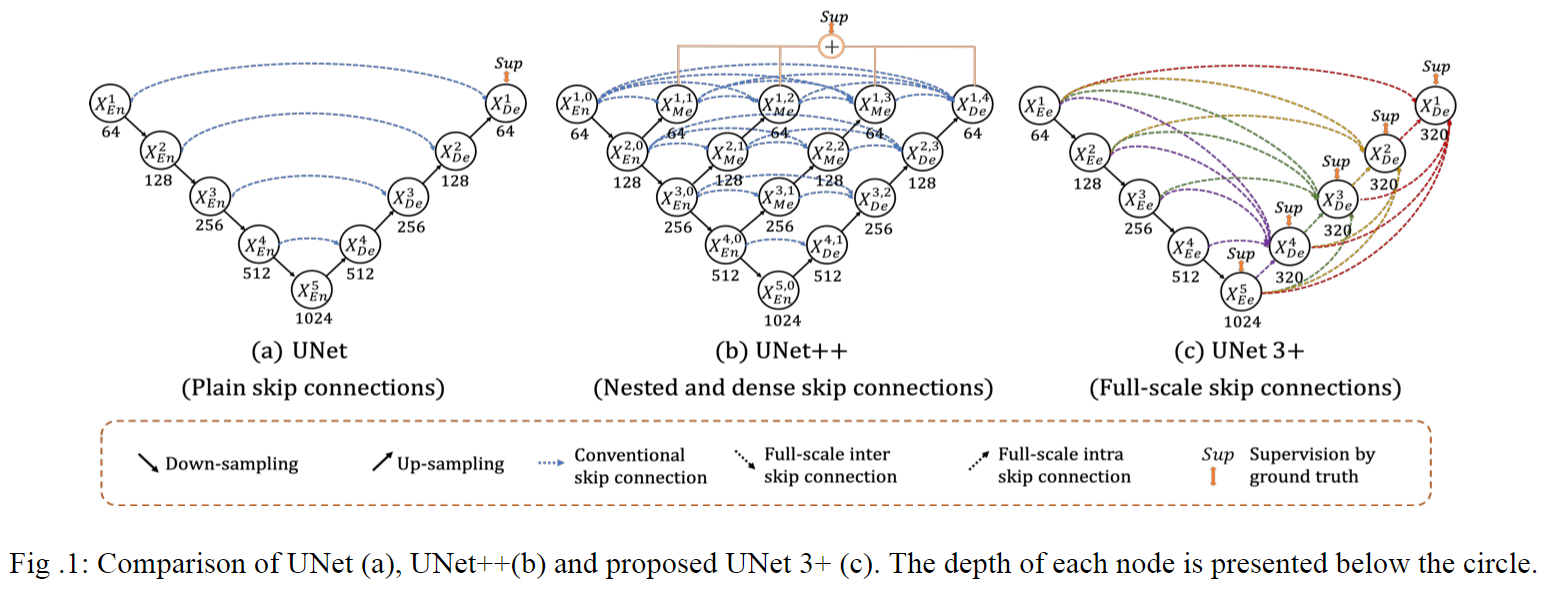
UNet(2015)是医学影像分割领域应用最广泛的的网络,它使用跳跃连接(skip connection)来结合来自解码器的高级语义特征图和来自编码器的相应尺度的低级语义特征图,其性能和网络中多尺度特征的融合密切相关。为了避免纯跳跃连接在语义上融合不相似的特征,此后的UNet++(2018)引入嵌套结构和密集的跳跃连接对网络进行了改进。而最新的UNet3+(2020)通过全尺度的跳跃连接和深度监督(deep supervisions)来融合深层和浅层特征的同时对各个尺度的特征进行监督,它还可以在减少网络参数的同时提高计算效率。
2.2. 模型介绍
Huang等人(2020)在论文中提出了UNet3+模型,Huang等人使用该模型在肝脏和脾脏数据集上进行广泛的实验,发现它的表现得到了提高并且超过了很多baselines。下面介绍一下UNet3+模型的三个创新点:
(1) 全尺度跳跃连接
UNet3+充分利用多尺度特征,引入全尺度跳跃连接(Full-scale Skip Connections),该连接结合了来自全尺度特征图的低级语义和高级语义,并且参数更少。
在许多分割实验的研究中,不同尺度的特征图展示着不同的信息:低级语义特征图捕捉丰富的空间信息,能够突出物体的边界;而高级语义特征图则体现了物体所在的位置信息。为此,UNet3+的每个解码器层都融合了来自编码器中的小尺度和同尺度的低级语义特征图,以及来自解码器的大尺度的高级语义特征图,这些特征图捕获了全尺度下的细粒度语义和粗粒度语义。
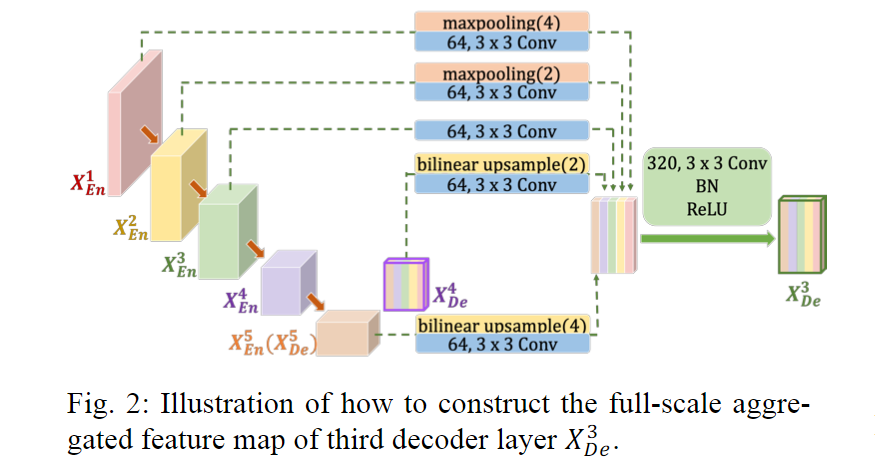
如上图所示,为了构造特征图,第3层解码器不仅需要接收同尺度编码器层的特征图,还需要接收小尺度编码器层的特征图和(为了统一特征图的分辨率,在接收前需进行下采样操作),同时也需要接收大尺度解码器层的特征图和(为了统一特征图的分辨率,在接收前需进行上采样操作)。在统一特征图的分辨率之后,我们还需用64个3×3的卷积核统一特征图的数量,以减少多余信息。在完成上述操作之后,我们就能用“通道维度拼接”的方法融合特征了,融合上述5个特征后便得到了320个特征图。接着,我们用320个3×3的卷积核对其进行卷积操作,最后通过批正则化(Batch Normalize)和ReLU(Rectified Linear Unit)便得到。
于是,特征图的计算公式可总结为:
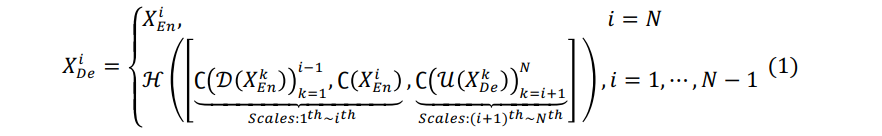
其中,变量表示沿着编码方向的编/解码层的编号,变量表示编码器的总数,函数代表卷积操作,函数和分别代表上采样和下采样操作,函数代表“特征融合”机制(即1个卷积层+1个批正则化层+1个ReLU函数层),代表“通道维度拼接”。
(2) 全尺度深度监督
UNet3+采用全尺度深度监督(Full-scale Deep Supervision),从全面的聚合特征图中学习层次表示,优化了混合损失函数以增强器官边界。
不同于UNet++对全分辨率特征图进行深度监督,UNet3+中每个解码器都有一个侧输出,它是由真实标准(ground truth)来进行监督的。为实现深度监督,每个解码器的侧输出都会被送入1个3×3卷积层、1个双线性上采样层以及1个sigmoid函数层中。
为了进一步增强器官边界,UNet3+提出了一种多尺度结构相似指数(Multi-Scale Structural Similarity index,MS-SSIM)损失函数来赋予模糊边界更大的权重。由于区域分布差异越大,MS-SSIM值越高,故UNet3+将更加关注模糊边界。假设我们从分割结果P和真实标准G中分别裁剪了两个N×N的块和,并且有和,那么我们可定义和的MS-SSIM损失函数为:
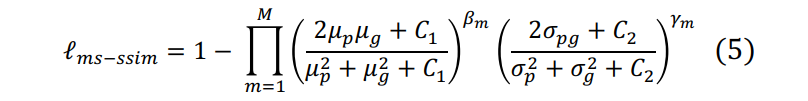
其中,表示尺度的总数(原作者将尺度总数设为5),和分别表示和的均值和方差,则表示和的协方差。分别表示这两部分在每个尺度中的相对重要性程度,而设置小常量的目的是避免出现除以0的异常情况。
UNet3+融合了focal损失函数、MS-SSIM损失函数和IoU损失函数,提出了一种用于三个不同层次级别(像素级、块级、图像级)分割的混合损失函数,它能捕获边界清晰的大尺度结构和精细结构。该混合损失函数的定义为:
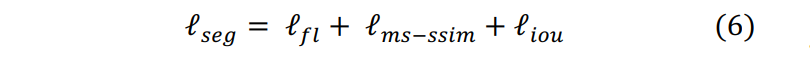
(3) 分类指导模块
UNet3+提出分类指导模块(Classification-guided Module,CGM),通过图像级分类联合训练,减少非器官图像的过度分割。
在大多数医学图像分割实验中,由于来自背景的噪声信息停留在较浅层次中,这导致非器官图像出现过度分割的现象。为解决这一问题,UNet3+增加了一个预测输入图像是否有器官的额外分类任务。
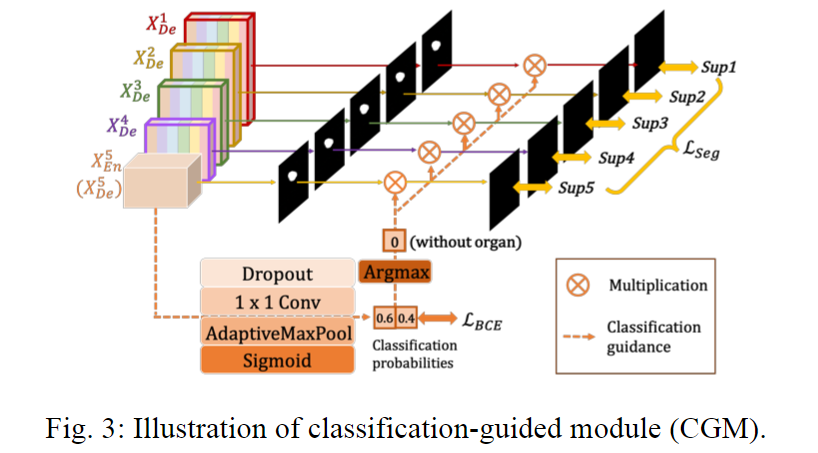
如上图所示,最深层的特征图依次通过Dropout层、1×1卷积层、最大池化层和Sigmoid函数层,以得到代表中有/无器官概率的二维张量。然后,我们可以用argmax函数处理二维张量,以得到仅包含0和1的二分类结果。接着,我们用这些分类结果与每个侧边分割输出相乘,以得到修正后的侧边分割输出。我们可以通过优化二分类的交叉损失函数,来获得更准确的分类结果,以此指导模型避免对非器官图像过度分割。
3. 代码实现
3.0. 前期准备
- 导入模块
注意:本案例仅适用于
Paddle 2.0+版本,建议根据显存大小合理调整超参数batch_size和img_size的大小!
1 | import cv2 |
- 设置超参数
1 | BATCH_SIZE = 4 # 每批次的样本数 |
3.1. 数据准备
- 解压数据集
由于数据集中的数据是以压缩包的形式存放的,因此我们需要先解压数据压缩包。
1 | if not os.path.isdir(DATA_PATH["img"]) or not os.path.isdir(DATA_PATH["lab"]): |
- 划分数据集
我们需要按9:1比例划分训练集和测试集,分别生成两个包含数据路径和标签路径映射关系的列表。
1 | train_list, test_list = [], [] # 存放图像路径与标签路径的映射 |
- 数据增强
数据増广(Data Augmentation),即数据增强,数据增强的目的主要是减少网络的过拟合现象,通过对训练图片进行变换可以得到泛化能力更强的网络,更好地适应应用场景。
由于实验模型较为复杂,直接训练容易发生过拟合,故在处理实验数据集时采用数据增强的方法扩充数据集的多样性。本实验中用到的数据增强方法有:随机改变亮度,随机改变对比度,随机改变饱和度,随机改变清晰度,随机旋转图像,随机翻转图像,随机加高斯噪声等。
1 | def random_brightness(img, lab, low=0.5, high=1.5): |
- 数据预处理
我们需要对数据集图像进行缩放和归一化处理。
1 | class MyDataset(Dataset): |
1 | train_dataset = MyDataset(train_list, data_mapper, image_augment) # 训练集 |
- 定义数据提供器
我们需要分别构建用于训练和测试的数据提供器,其中训练数据提供器是乱序、按批次提供数据的。
1 | train_loader = DataLoader(train_dataset, # 训练数据集 |
3.2. 网络配置
本次实验使用的是UNet3+模型,UNet系列模型包含下采样(编码器,特征提取)和上采样(解码器,分辨率还原)两个阶段,因模型结构比较像U型而得名。
- 定义网络初始化函数
1 | def init_weights(net, init_type="normal"): |
- 构建编码器
1 | class Encoder(nn.Layer): |
- 构建解码器
1 | class Decoder(nn.Layer): |
- 定义网络结构
1 | class UNet3Plus(nn.Layer): |
- 实例化模型
1 | model = UNet3Plus(n_classes=N_CLASSES, deep_sup=False, set_cgm=False) |
- 定义损失函数
1 | class DiceLoss(nn.Layer): |
- 定义评估方法
1 | def dice_func(pred: np.ndarray, mask: np.ndarray, |
3.3 模型训练
1 | model.train() # 开启训练模式 |
模型训练的结果如下:
1 | Epoch: 0,Batch: 0,Loss:0.41813 |
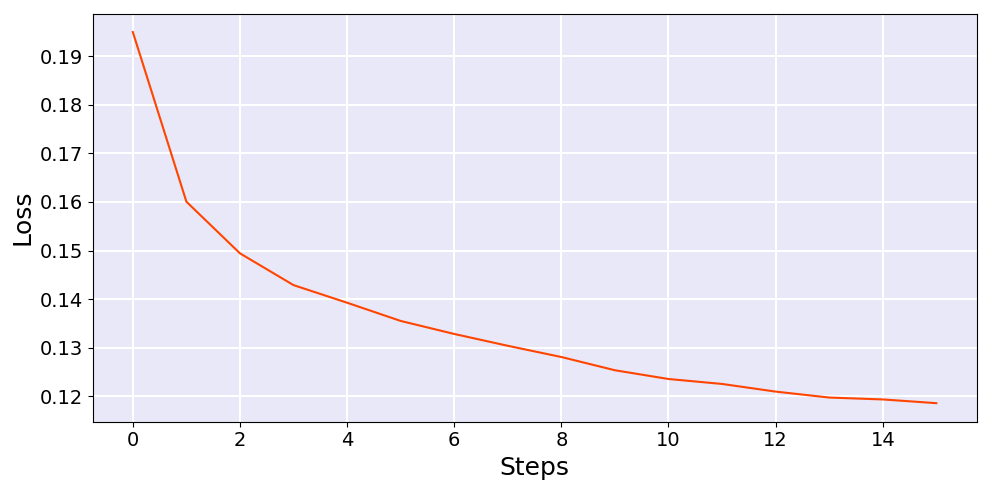
- 可视化训练过程
1 | fig = plt.figure(figsize=[10, 5]) |
3.4. 模型评估
1 | model.eval() # 开启评估模式 |
模型评估的结果如下:
1 | Eval Dice: 0.94400 |
3.5. 模型预测
1 | def show_result(img_path, lab_path, pred): |
1 | model.eval() # 开启评估模式 |
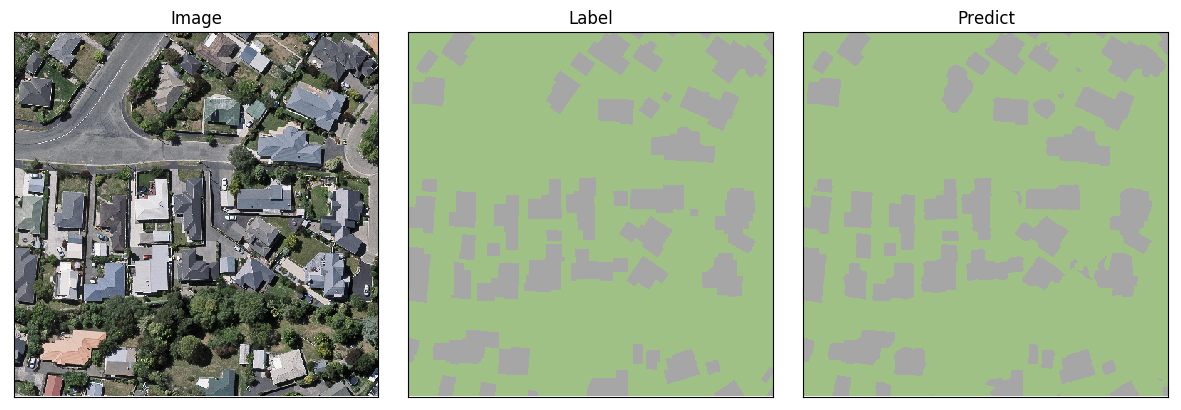
第1组图像分割结果如下:
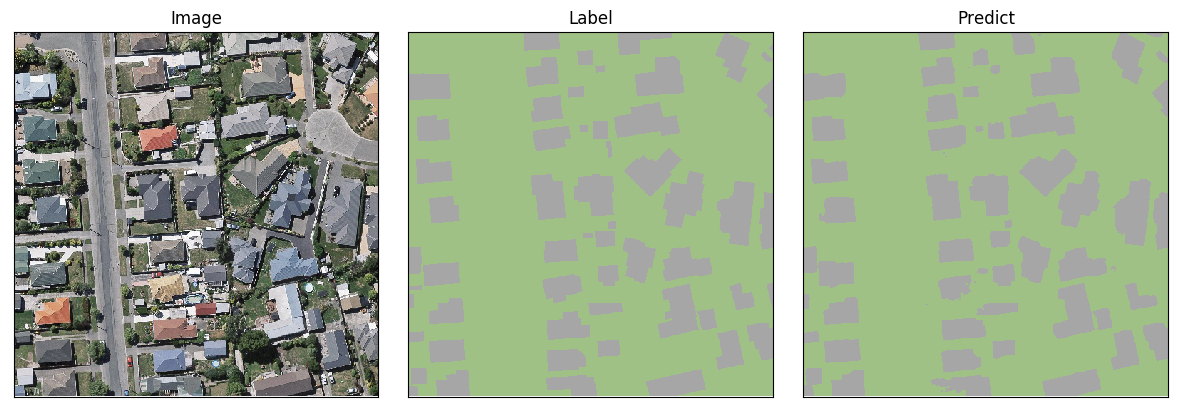
第2组图像分割结果如下:
写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 - AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 - AI Studio,来AI Studio互粉吧,等你哦~