1. 项目准备
1.1. 问题导入
深度强化学习是将深度学习和强化学习相结合起来的方法,本文将使用深度强化学习DQN算法训练智能体解决小车上山(Mountain Car)问题。
1.2. 环境介绍
本次实验所用的训练环境为gym库的“小车上山”(MountainCar-v0)环境。
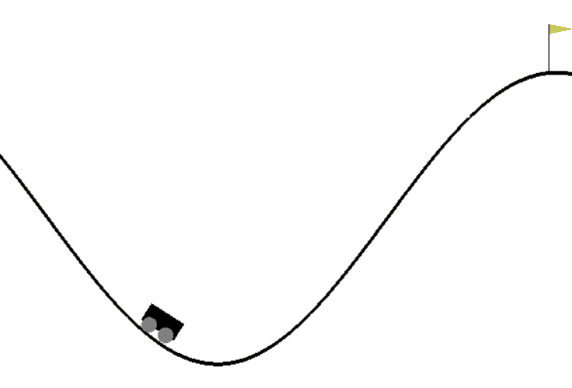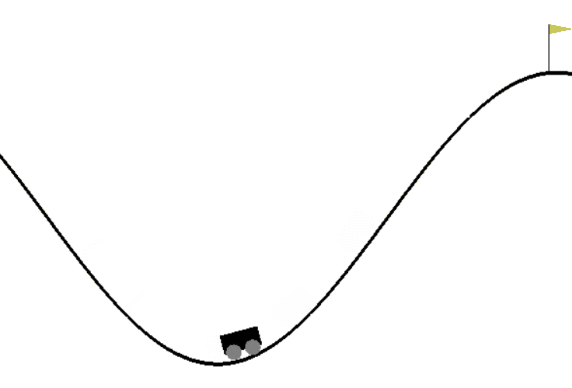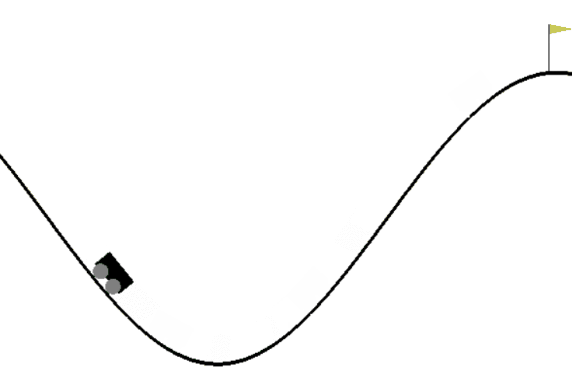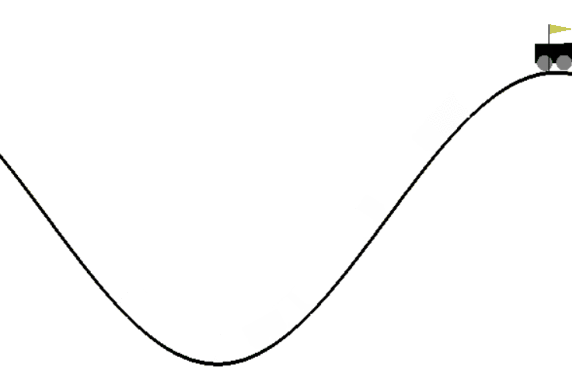
如上图所示,为了解决该问题,智能体需要通过前后移动车,让它到达旗帜的位置。
2. DQN算法
-
相关背景
(1)传统Q表格难以装下过多的Q值,并且Q值越多查表速度越慢;
(2)使用神经网络建立值函数可以模拟Q表格,只需要存储少量参数;
(3)神经网络能够自动提取输入的特征,具有较好的泛化能力。
-
算法介绍
深度Q学习网络(Deep Q-Learning Network,DQN)算法是DeepMind团队于2014年提出的强化学习算法,它成功开启了深度强化学习的新时代。DQN算法本质上是对Q-learning算法的改进,并且它们的更新方式一致。
-
算法特点
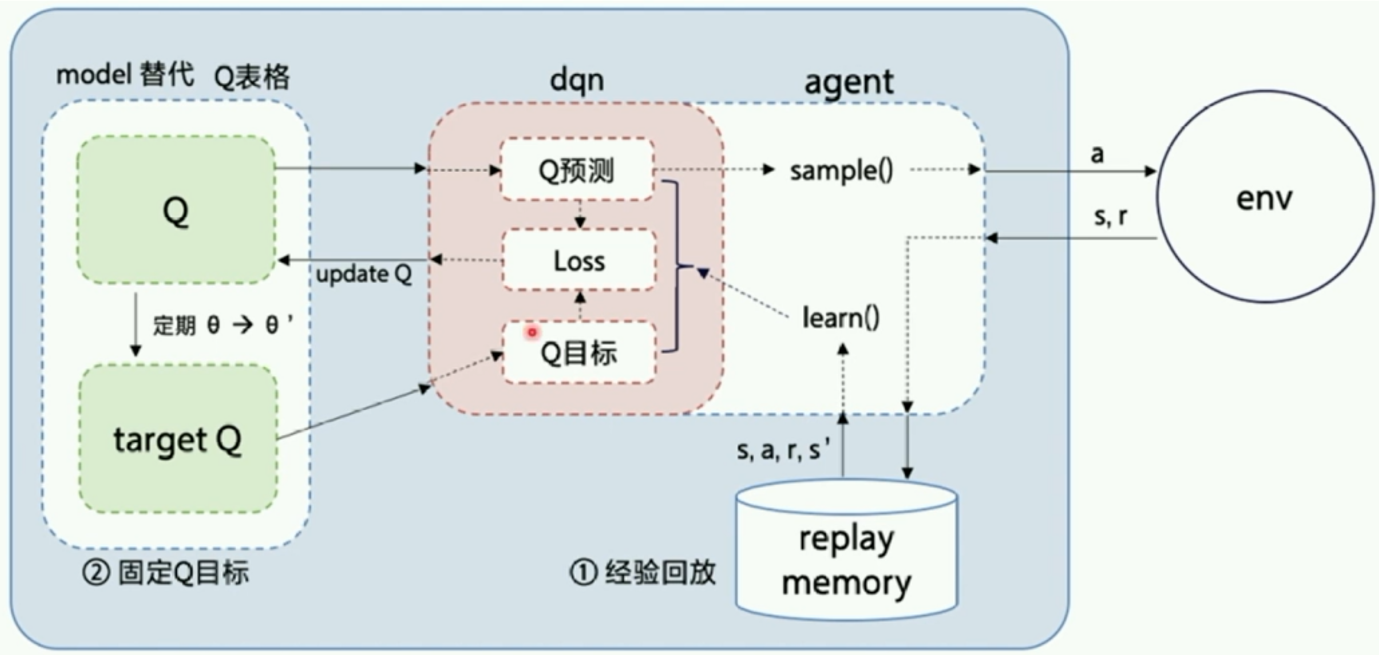
(1)经验回放 (Experience replay)
(2)固定Q目标 (Fixed Q target)
(3)用Q网络代替Q表格
3. 实验步骤
3.0. 前期准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import gym
import numpy as np
import random
import collections
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.optimizer import Adam
from copy import deepcopy
from parl import Model as parlModel
from parl import Algorithm as parlAlg
from parl import Agent as parlAgent
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
GAMMA = 0.999
MODEL_LR = 1e-4
BATCH_SIZE = 128
MEMORY_SIZE = 400_000
MEMORY_WARMUP = 50
EVAL_EPOCHS = 5
EVAL_GAP = 200
TRAIN_EPOCHS = 3000
UPDATE_FREQ = 10_000
EPSILON = {
"value": 0.50,
"decay": 1e-6,
"final": 0.01,
}
MODEL_PATH = "DQN.pdparams"
|
3.1. 搭建网络模型(Model)
Model用来定义前向(forward)网络,用户可以自由的定制自己的网络结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
| class Model(parlModel):
def __init__(self, obs_dim, act_dim, hidden_size=128):
super(Model, self).__init__()
self.fc1 = nn.Linear(obs_dim, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, act_dim)
def forward(self, obs):
s = F.relu(self.fc1(obs))
s = F.relu(self.fc2(s))
Q = self.fc3(s)
return Q
|
3.2. 搭建算法(Algorithm)
Algorithm定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class DQN(parlAlg):
def __init__(self, model, gamma, model_lr):
self.model = model
self.tgt_model = deepcopy(model)
self.gamma = gamma
self.optimizer = Adam(
learning_rate=model_lr,
parameters=self.model.parameters()
)
def predict(self, obs):
return self.model(obs)
def learn(self, obs, action, reward, next_obs, done):
pred_vals = self.model(obs)
act_onehot = F.one_hot(
paddle.squeeze(action, axis=-1),
num_classes=pred_vals.shape[-1]
)
pred_Q = paddle.sum(
paddle.multiply(pred_vals, act_onehot),
axis=1, keepdim=True
)
with paddle.no_grad():
max_val = self.tgt_model(next_obs).max(1, keepdim=True)
tgt_Q = reward + (1 - done) * self.gamma * max_val
loss = F.mse_loss(pred_Q, tgt_Q)
self.optimizer.clear_grad()
loss.backward()
self.optimizer.step()
return loss
def sync_target(self):
self.model.sync_weights_to(self.tgt_model)
|
3.3. 搭建智能体(Agent)
Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class Agent(parlAgent):
def __init__(self, alg, act_dim, epsilon, update_freq):
super(Agent, self).__init__(algorithm=alg)
self.act_dim = act_dim
self.epsilon = epsilon
self.update_freq = update_freq
self.steps = 0
def sample(self, obs):
''' 根据当前状态探索动作 '''
self.steps += 1
if np.random.rand() < self.epsilon["value"]:
act = np.random.choice(self.act_dim)
else:
act = self.predict(obs)
self.epsilon["value"] = max(self.epsilon["final"],
self.epsilon["value"] - self.epsilon["decay"])
return act
def predict(self, obs):
''' 根据当前状态预测最优动作 '''
obs = paddle.to_tensor(obs, dtype="float32")
pred_Q = self.alg.predict(obs)
return pred_Q.argmax().numpy()[0]
def learn(self, obs, act, reward, next_obs, done):
if self.steps % self.update_freq == 0:
self.alg.sync_target()
act = np.expand_dims(act, -1)
reward = np.expand_dims(reward, -1)
done = np.expand_dims(done, -1)
loss = self.alg.learn(
paddle.to_tensor(obs, dtype="float32"),
paddle.to_tensor(act, dtype="int32"),
paddle.to_tensor(reward, dtype="float32"),
paddle.to_tensor(next_obs, dtype="float32"),
paddle.to_tensor(done, dtype="float32")
)
return loss.numpy()[0]
|
3.4. 搭建经验回放池
经验回放池ReplayMemory用于存储多条经验,实现经验回放,供智能体进行学习。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
def __len__(self):
return len(self.buffer)
def init_memory(self, env, agent, warmup):
''' 向经验池内加入初始数据,避免开始训练时的样本数不够
* `env`(gym.Env): 训练环境
* `agent`(Agent): 强化学习智能体
* `warmup`(int): 需要探索的轮数
'''
print("\033[33m Start to initialize replay memory... \033[0m")
for ep in range(warmup):
obs, done = env.reset(), False
while not done:
act = agent.sample(obs)
next_obs, reward, done, _ = env.step(act)
self.buffer.append((obs, act, reward, next_obs, done))
obs = next_obs
print("\033[33m Initialize replay memory successfully! \033[0m")
def append(self, exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, act_batch, reward_batch = [], [], []
next_obs_batch, done_batch = [], []
for experience in mini_batch:
obs, act, reward, next_obs, done = experience
obs_batch.append(obs)
act_batch.append(act)
reward_batch.append(reward)
next_obs_batch.append(next_obs)
done_batch.append(done)
return (np.array(obs_batch).astype("float32"),
np.array(act_batch).astype("int32"),
np.array(reward_batch).astype("float32"),
np.array(next_obs_batch).astype("float32"),
np.array(done_batch).astype("float32"))
|
3.5. 训练与评估
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| def run_episode(env, agent, rpm):
total_reward = 0
step, done = 0, False
obs = env.reset()
while not done:
step += 1
act = agent.sample(obs)
next_obs, reward, done, _ = env.step(act)
rpm.append((obs, act, reward, next_obs, done))
(batch_obs, batch_action, batch_reward,
batch_next_obs, batch_done) = rpm.sample(BATCH_SIZE)
agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs, batch_done)
total_reward += reward
obs = next_obs
return total_reward
def evaluate(env, agent, render=False):
eval_reward = []
for ep in range(EVAL_EPOCHS):
obs = env.reset()
done, ep_reward = False, 0
while not done:
act = agent.predict(obs)
obs, reward, done, _ = env.step(act)
ep_reward += reward
if render:
env.render()
eval_reward.append(ep_reward)
return np.mean(eval_reward)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| env = gym.make('MountainCar-v0')
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.n
model = Model(obs_dim, act_dim)
alg = DQN(model, GAMMA, MODEL_LR)
agent = Agent(alg, act_dim, EPSILON, UPDATE_FREQ)
rpm = ReplayMemory(MEMORY_SIZE)
rpm.init_memory(env, agent, MEMORY_WARMUP)
for episode in range(TRAIN_EPOCHS + 1):
train_reward = run_episode(env, agent, rpm)
if episode % EVAL_GAP == 0:
test_reward = evaluate(env, agent, render=True)
print('【Eval】Episode: %d; ε_greed: %.3f; Reward: %.1f' %
(episode, agent.epsilon["value"], test_reward))
agent.save(MODEL_PATH)
|
训练及评估的结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| 【Eval】Episode: 0; ε_greed: 0.490; Reward: -200.0
【Eval】Episode: 200; ε_greed: 0.450; Reward: -123.6
【Eval】Episode: 400; ε_greed: 0.410; Reward: -110.0
【Eval】Episode: 600; ε_greed: 0.370; Reward: -139.4
【Eval】Episode: 800; ε_greed: 0.330; Reward: -124.0
【Eval】Episode: 1000; ε_greed: 0.290; Reward: -200.0
【Eval】Episode: 1200; ε_greed: 0.250; Reward: -200.0
【Eval】Episode: 1400; ε_greed: 0.210; Reward: -200.0
【Eval】Episode: 1600; ε_greed: 0.171; Reward: -133.8
【Eval】Episode: 1800; ε_greed: 0.136; Reward: -134.4
【Eval】Episode: 2000; ε_greed: 0.103; Reward: -200.0
【Eval】Episode: 2200; ε_greed: 0.071; Reward: -200.0
【Eval】Episode: 2400; ε_greed: 0.041; Reward: -123.6
【Eval】Episode: 2600; ε_greed: 0.011; Reward: -110.0
【Eval】Episode: 2800; ε_greed: 0.010; Reward: -139.4
【Eval】Episode: 3000; ε_greed: 0.010; Reward: -124.0
|
写在最后