强化学习相关理论基础
1. 强化学习
1.1. 核心思想
强化学习(Reinforcement Learning,RL)研究的是智能体如何决策以获得最大效益。
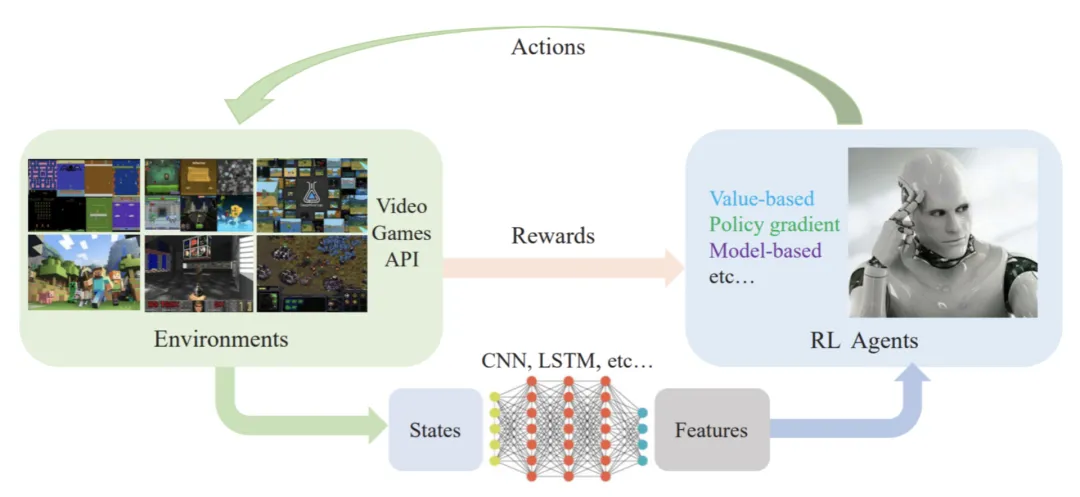
如上图所示,智能体agent在训练环境environment中学习,根据环境的全局状态state或观测到的局部观测值observation,执行相应的动作action,并根据环境的反馈reward来指导自己。智能体通过不断的试错探索、吸取经验教训,持续不断地优化策略,不断提升模型的正确决策的能力,以便从环境中拿到更好的反馈,最终实现“最小化风险、最大化收益”的目标。
1.2. 区别联系
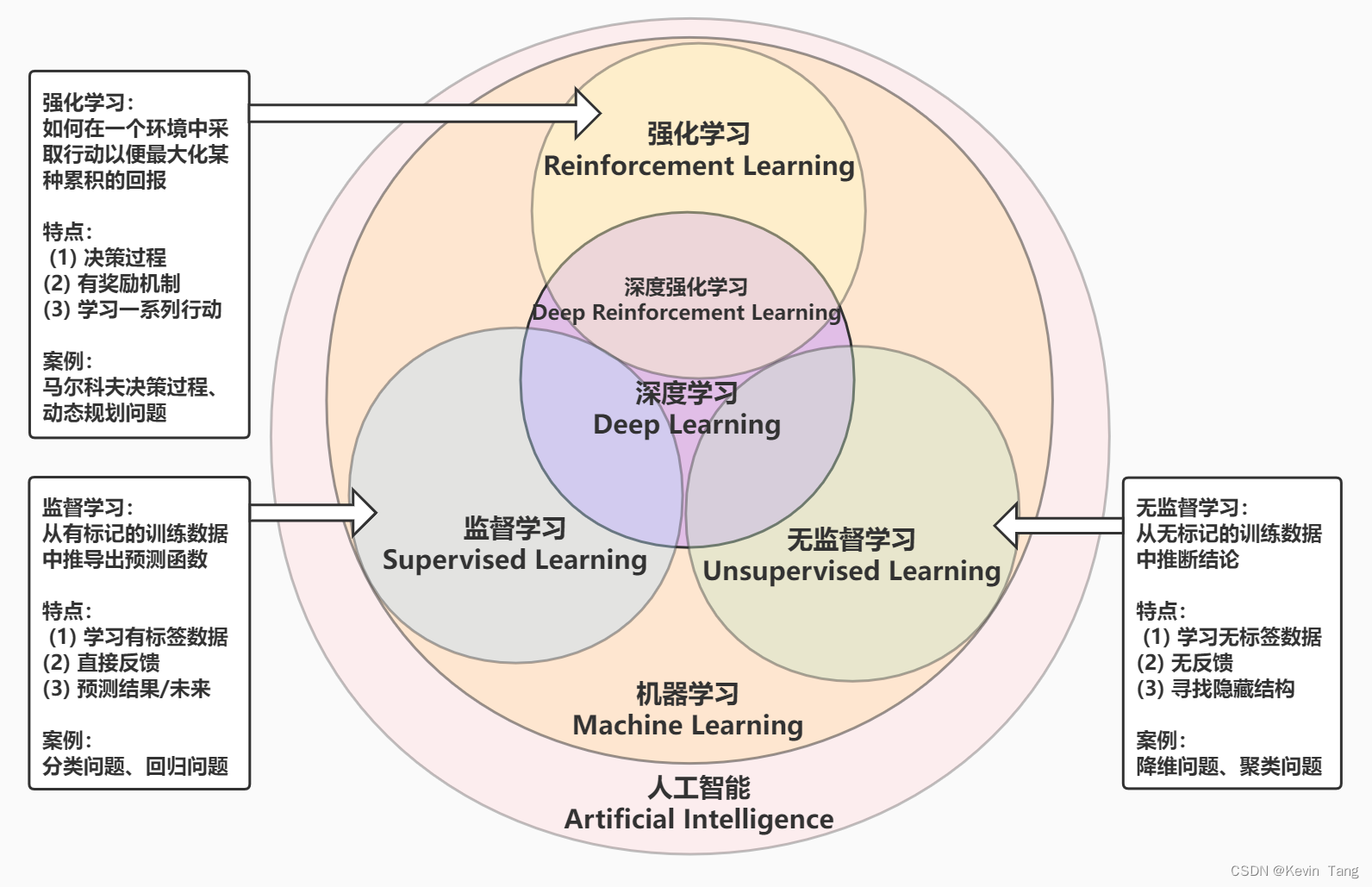
如下图所示,机器学习(Machine Learning,ML)算法通常可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习,深度学习通常可以与这些方法一起使用。
-
监督学习
监督学习使用带标签的数据进行学习,主要寻找输入与输出之间的映射关系,它主要用于处理认知问题,适用于解决分类问题、回归问题等。 -
无监督学习
无监督学习使用无标签的数据进行学习,主要寻找数据之间隐藏的关系,它适用于解决聚类问题等。 -
强化学习
强化学习主要处理如何基于环境进行最优决策的问题,“试错”是强化学习的核心特点,它适用于解决马尔科夫决策问题、动态规划问题等。
1.3. 算法分类
(1)按照环境是否已知可以分为Model-Based和Model-Free。
比较常用的是后者,因为大多数情况下,智能体所处的环境是未知的。
(2)按照应用环境可以分为基于离散控制场景的强化学习算法和基于连续控制场景的强化学习算法。
如下图所示,前者常见的有:DQN算法、DDQN算法等,后者常见的有DDPG算法、TD3算法、SAC算法等。
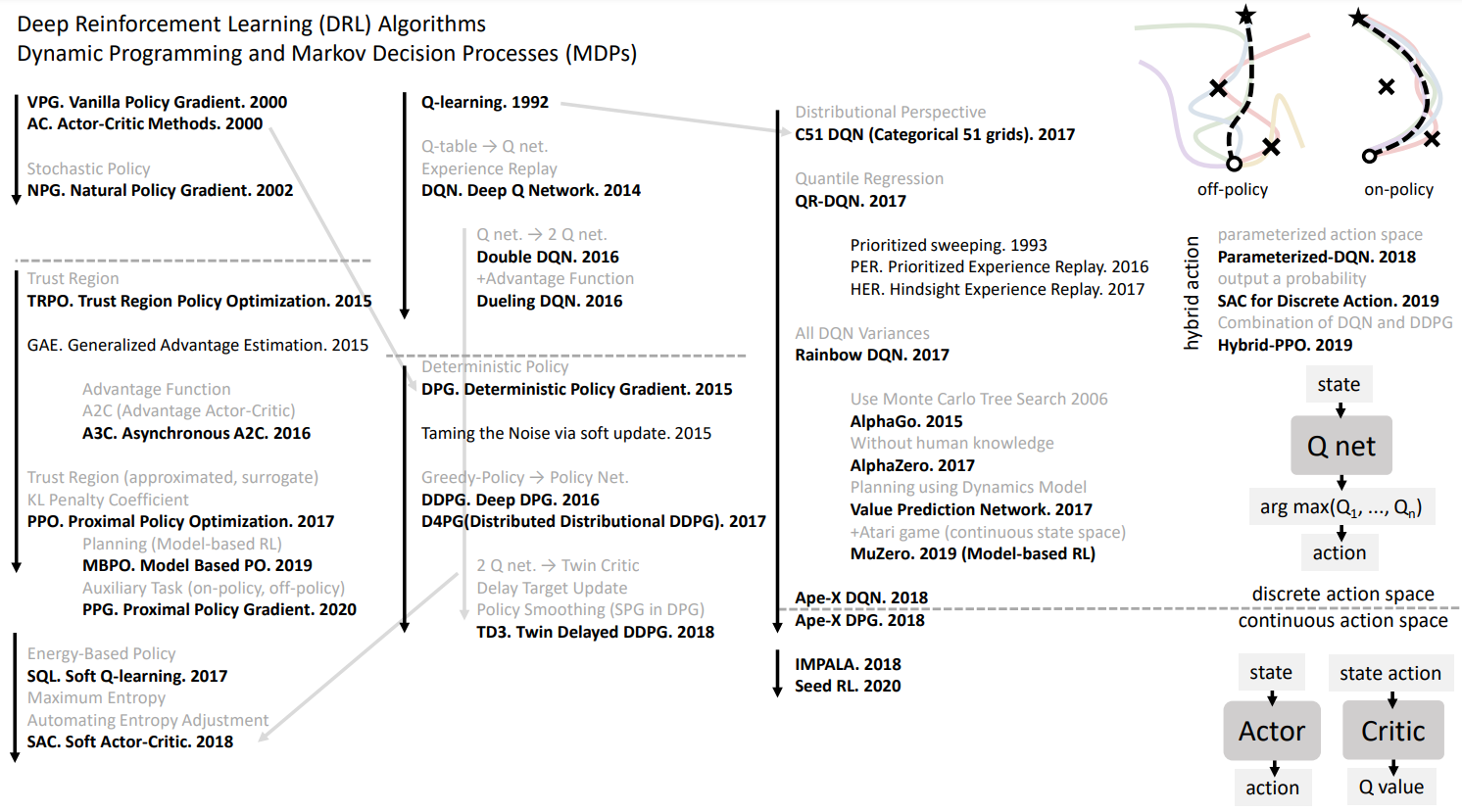
(图片来源:曾伊言 - 如何选择深度强化学习算法?)
(3)按照学习方式可以分为On-Policy和Off-Policy。
Sarsa算法就属于On-Policy算法,Q-learning算法就属于Off-Policy算法。
(4)按照学习目标可以分为Value-Based和Policy-Based。
- 基于价值(Value Based)的算法需要先将Q函数优化到最优,然后再选最优策略;
- 基于策略(Policy Based)的算法直接优化策略函数输出最优动作。
2. 应用场景举例
接下来,介绍强化学习领域的两个前景广阔的应用场景:
2.1. 个性化推荐
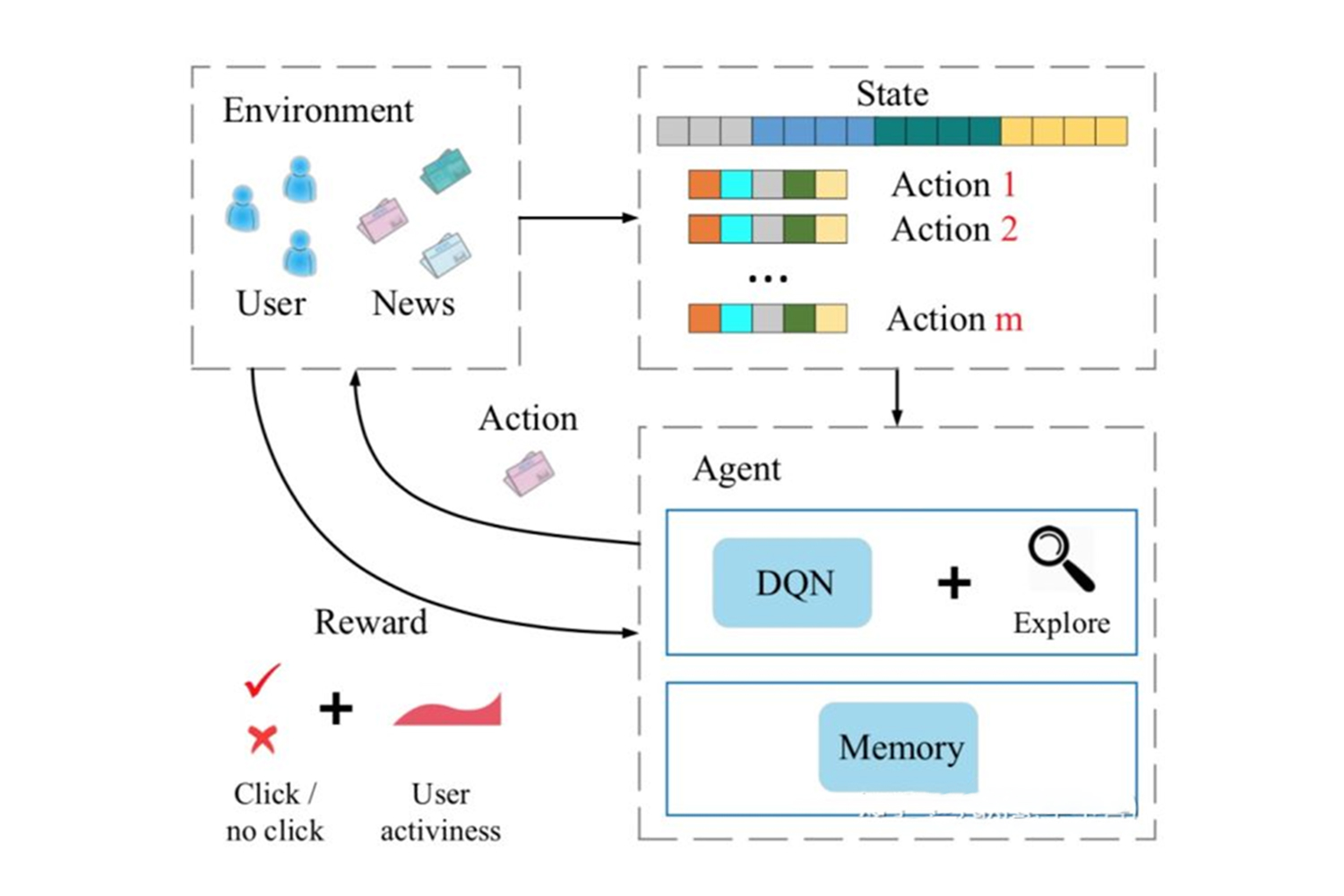
-
设计思路
在强化学习的框架之下,推荐系统被视作一个智能体(agent),用户当前的行为特征被抽象成为状态(state),待推荐的对象(如商品/新闻)则被当作动作(action)。在每次推荐交互中,系统依据用户的状态,选择合适的动作,以最大化特定的长效目标(如点击总数或停留时长)。推荐系统与用户交互过程中所产生的行为数据被组织成为经验(experience),用以记录相应动作产生的奖励(reward)以及状态转移(state-transition)。基于不断积累的经验,强化学习算法得出策略(policy),用以指导特定状态下最优的动作选取。 -
应用场景
适用于构建资讯推荐系统、商品推荐系统等 -
主要挑战
推荐场景下的可获取的交互数据往往规模有限且奖励信号稀疏(reward-sparsity),这就使得简单地套用既有算法难以取得令人满意的实际效果。如何运用有限的用户交互得到有效的决策模型将是算法进一步提升的主要方向。
2.2. 投资组合决策
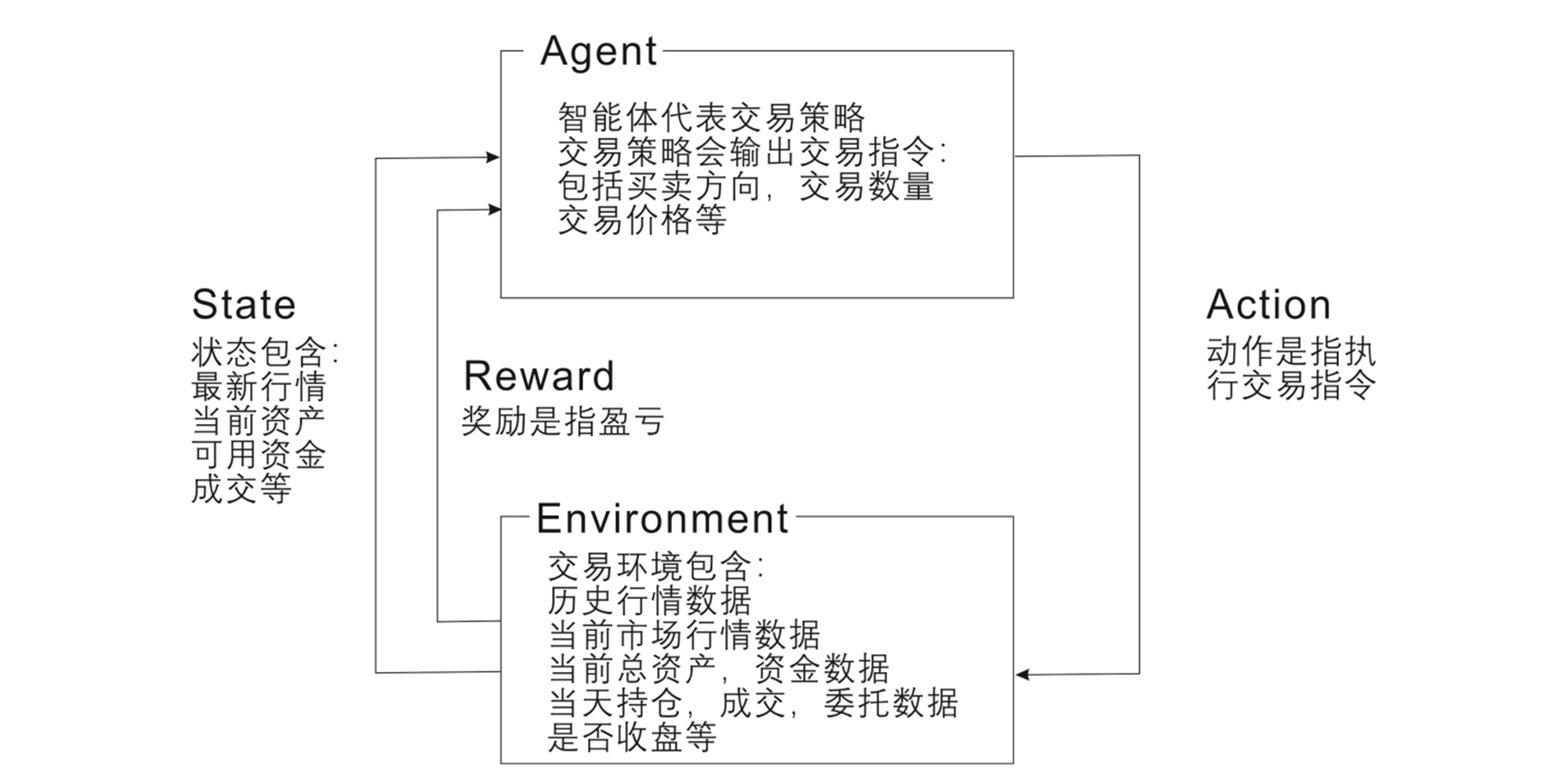
-
设计思路
监督学习模型可用来预测未来的价格,然而它们并不适用于在特定价格下做出决策。强化学习正是一种擅长“动态规划”和“决策”的算法,我们可以构建虚拟交易环境,通过市场基准标准对智能体的行为进行评估,确保智能体正确做出持有、购买或是出售的决定,以保证最佳收益。 -
应用场景
适用于解决多股票/基金交易问题、项目投资组合问题等
写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是我的个人主页:个人主页 - AI Studio,来AI Studio互粉吧,等你哦~