1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
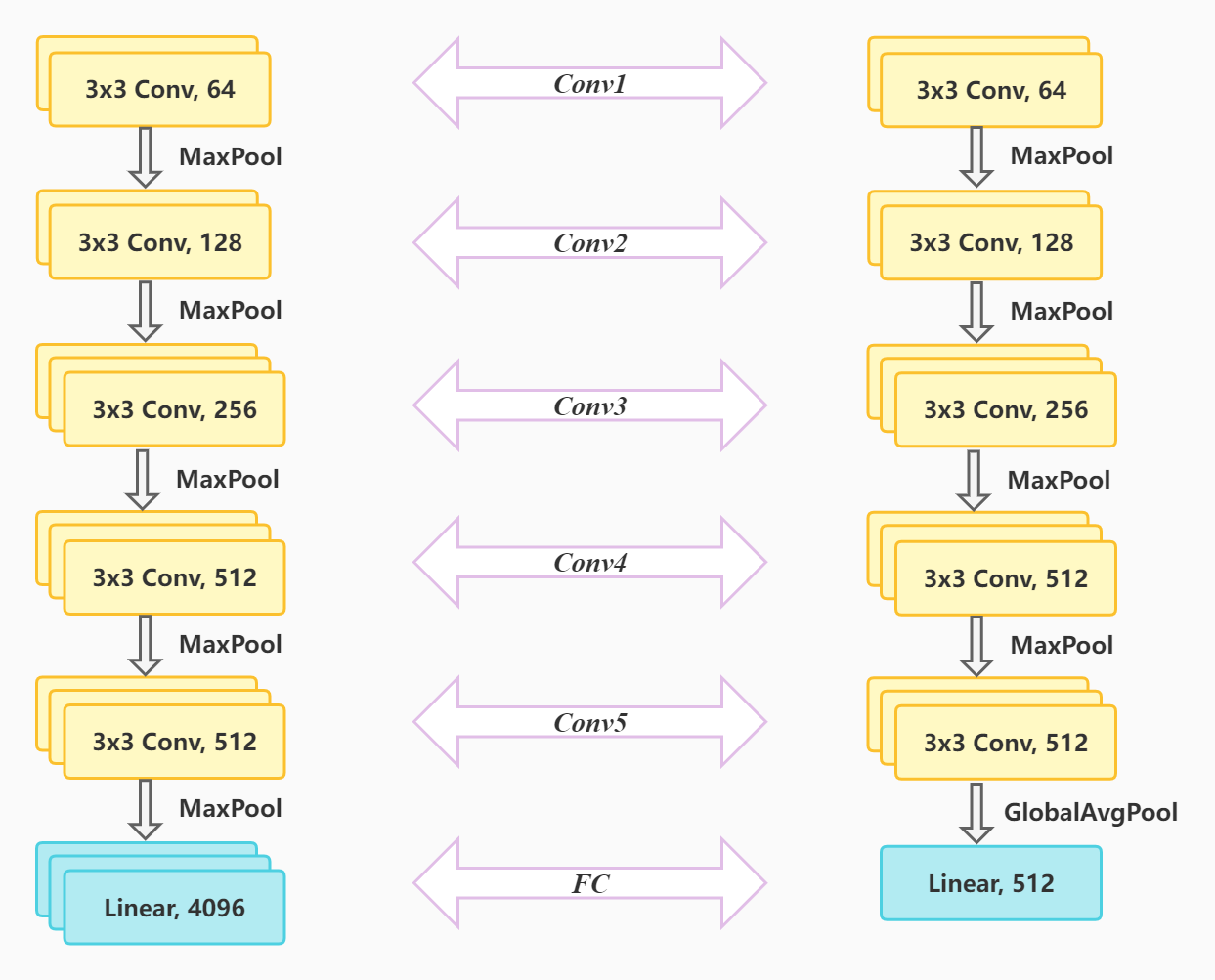
| class VGG(nn.Layer):
def __init__(self, in_channels=3, n_classes=2, mtype=16, global_pool=False):
'''
* `in_channels`: 输入的通道数
* `n_classes`: 输出分类数量
* `mtype`: VGG类型 (11 or 13 or 16 or 19)
* `global_pool`: 是否用全局平均池化改进VGG
'''
super(VGG, self).__init__()
if mtype == 11:
nums = [1, 1, 2, 2, 2]
elif mtype == 13:
nums = [2, 2, 2, 2, 2]
elif mtype == 16:
nums = [2, 2, 3, 3, 3]
elif mtype == 19:
nums = [2, 2, 4, 4, 4]
else:
raise NotImplementedError("The [mtype] must in [11, 13, 16, 19].")
self.conv1 = ConvPool([in_channels, 64, 3, 1, 1], [2, 2], nums[0], "max")
self.conv2 = ConvPool([64, 128, 3, 1, 1], [2, 2], nums[1], "max")
self.conv3 = ConvPool([128, 256, 3, 1, 1], [2, 2], nums[2], "max")
self.conv4 = ConvPool([256, 512, 3, 1, 1], [2, 2], nums[3], "max")
if global_pool:
self.conv5 = ConvPool([512, 512, 3, 1, 1], [], nums[4], "global")
self.linear = nn.Sequential(nn.Flatten(1, -1),
nn.Linear(512, n_classes))
else:
self.conv5 = ConvPool([512, 512, 3, 1, 1], [2, 2], nums[4], "max")
self.linear = nn.Sequential(nn.Flatten(1, -1),
nn.Linear(512*7*7, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, n_classes))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
y = self.linear(x)
return y
|