1. 项目准备
1.1. 问题导入
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题。本实验将使用经典神经网络模型AlexNet预测手势图片所表示的数字。
1.2. 数据集简介
本次实验使用的数据集是由土耳其一所中学制作,数据集由Main文件夹中的训练/测试数据集和Infer文件夹中的预测数据集组成,包含0-9共10种数字的手势图片,实验图片都是大小为100 * 100像素、RGB格式的图像。
这是数据集的下载链接:手势识别数据集 - AI Studio
2. AlexNet模型
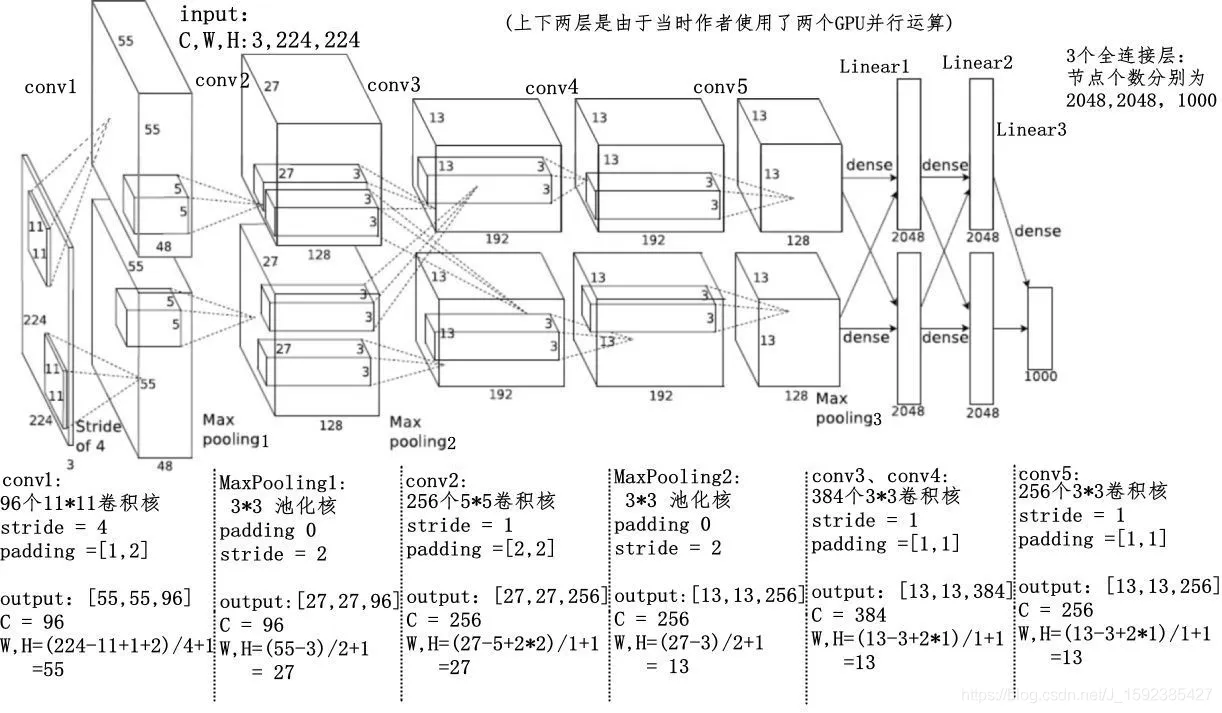
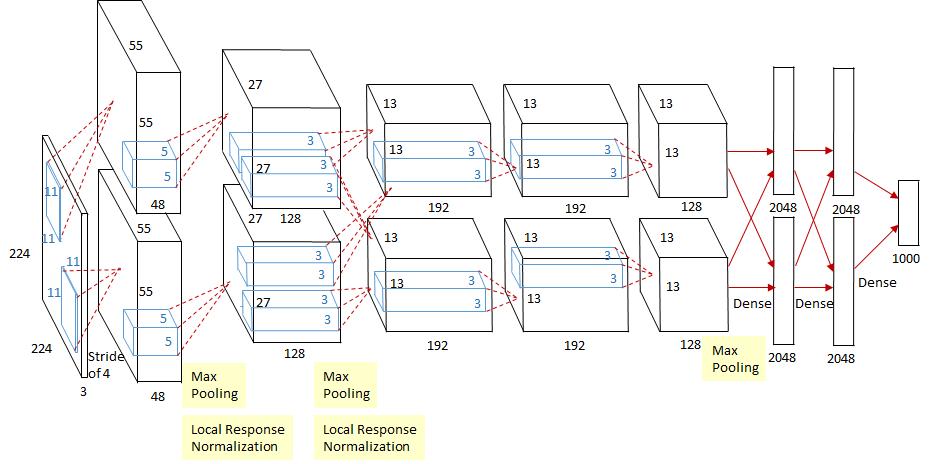
得益于硬件的发展(GPU的使用等)和各种算法的改进,在2012的ImageNet图像分类竞赛中,AlexeNet模型以远超第二名的成绩夺冠。AlexNet模型是Hinton及其学生Alex Krizhevsky等人(2012)在论文 中提出的网络模型,也是在那年之后,更多的更深的神经网络被提出,卷积神经网络乃至深度学习重新引起了广泛的关注。AlexNet模型的网络结构如下图所示。
3. 实验步骤
3.0. 前期准备
注意:本案例仅适用于PaddlePaddle 2.0+版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import osimport zipfileimport randomimport numpy as npfrom PIL import Imageimport matplotlib.pyplot as pltimport paddlefrom paddle import nnfrom paddle import metric as Mfrom paddle.io import DataLoader, Datasetfrom paddle.nn import functional as Ffrom paddle.optimizer import Adamfrom paddle.optimizer.lr import NaturalExpDecay
1 2 3 4 5 6 7 8 9 10 11 12 13 BATCH_SIZE = 32 CLASS_DIM = 10 EPOCHS = 10 LOG_GAP = 30 INIT_LR = 3e-4 LR_DECAY = 0.5 SRC_PATH = "./data/Gestures.zip" DST_PATH = "./data" DATA_PATH = DST_PATH + "/Main" INFER_PATH = DST_PATH + "/Infer" MODEL_PATH = "AlexNet.pdparams"
3.1. 数据准备
解压数据集
1 2 3 4 5 if not os.path.isdir(DATA_PATH) or not os.path.isdir(INFER_PATH): z = zipfile.ZipFile(SRC_PATH, "r" ) z.extractall(path=DST_PATH) z.close() print ("数据集解压完成!" )
划分数据集
1 2 3 4 5 6 7 8 9 10 11 train_list, test_list = [], [] file_folders = os.listdir(DATA_PATH) for folder in file_folders: imgs = os.listdir(os.path.join(DATA_PATH, folder)) for idx, img in enumerate (imgs): path = os.path.join(DATA_PATH, folder, img) if idx % 10 == 0 : test_list.append([path, folder]) else : train_list.append([path, folder])
数据预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class MyDataset (Dataset ): ''' 自定义的数据集类 ''' def __init__ (self, label_list, transform ): ''' * `label_list`: 标签与文件路径的映射列表 * `transform`:数据处理函数 ''' super (MyDataset, self).__init__() random.shuffle(label_list) self.label_list = label_list self.transform = transform def __getitem__ (self, index ): ''' 根据位序获取对应数据 ''' img_path, label = self.label_list[index] img = self.transform(img_path) return img, int (label) def __len__ (self ): ''' 获取数据集样本总数 ''' return len (self.label_list) def data_mapper (img_path, show=False ): ''' 图像处理函数 ''' img = Image.open (img_path) if show: display(img) img = img.resize((224 , 224 ), Image.ANTIALIAS) img = np.array(img).astype("float32" ) img = img.transpose((2 , 0 , 1 )) img = paddle.to_tensor(img / 255 ) return img
1 2 train_dataset = MyDataset(train_list, data_mapper) test_dataset = MyDataset(test_list, data_mapper)
定义数据提供器
1 2 3 4 5 6 7 8 9 10 11 train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, num_workers=0 , shuffle=True , drop_last=False ) test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, num_workers=0 , shuffle=False , drop_last=False )
3.2. 网络配置
AlexNet模型网络结构如下图所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class AlexNet (nn.Layer): def __init__ (self, in_channels=3 , n_classes=10 ): ''' * `in_channels`: 输入的通道数 * `n_classes`: 输出分类数量 ''' super (AlexNet, self).__init__() self.conv1 = nn.Conv2D(in_channels, 96 , 11 , stride=4 , padding=2 ) self.pool1 = nn.MaxPool2D(3 , 2 ) self.conv2 = nn.Conv2D(96 , 256 , 5 , stride=1 , padding=2 ) self.pool2 = nn.MaxPool2D(3 , 2 ) self.conv3 = nn.Conv2D(256 , 384 , 3 , stride=1 , padding=1 ) self.conv4 = nn.Conv2D(384 , 384 , 3 , stride=1 , padding=1 ) self.conv5 = nn.Conv2D(384 , 256 , 3 , stride=1 , padding=1 ) self.pool3 = nn.MaxPool2D(3 , 2 ) self.fc1 = nn.Linear(256 *6 *6 , 4096 ) self.drop1 = nn.Dropout(0.25 ) self.fc2 = nn.Linear(4096 , 4096 ) self.drop2 = nn.Dropout(0.25 ) self.fc3 = nn.Linear(4096 , n_classes) def forward (self, x ): x = F.relu( self.conv1(x) ) x = self.pool1(x) x = F.relu( self.conv2(x) ) x = self.pool2(x) x = F.relu( self.conv3(x) ) x = F.relu( self.conv4(x) ) x = F.relu( self.conv5(x) ) x = self.pool3(x) x = paddle.flatten(x, 1 , -1 ) x = F.relu( self.fc1(x) ) x = self.drop1(x) x = F.relu( self.fc2(x) ) x = self.drop2(x) y = self.fc3(x) return y
1 model = AlexNet(in_channels=3 , n_classes=CLASS_DIM)
3.3. 模型训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 model.train() scheduler = NaturalExpDecay( learning_rate=INIT_LR, gamma=LR_DECAY ) optimizer = Adam( learning_rate=scheduler, parameters=model.parameters() ) loss_arr, acc_arr = [], [] for ep in range (EPOCHS): for batch_id, data in enumerate (train_loader()): x_data, y_data = data y_data = y_data[:, np.newaxis] y_pred = model(x_data) acc = M.accuracy(y_pred, y_data) loss = F.cross_entropy(y_pred, y_data) if batch_id != 0 and batch_id % LOG_GAP == 0 : print ("Epoch:%d,Batch:%3d,Loss:%.5f,Acc:%.5f" \ % (ep, batch_id, loss, acc)) acc_arr.append(acc.item()) loss_arr.append(loss.item()) optimizer.clear_grad() loss.backward() optimizer.step() scheduler.step() paddle.save(model.state_dict(), MODEL_PATH)
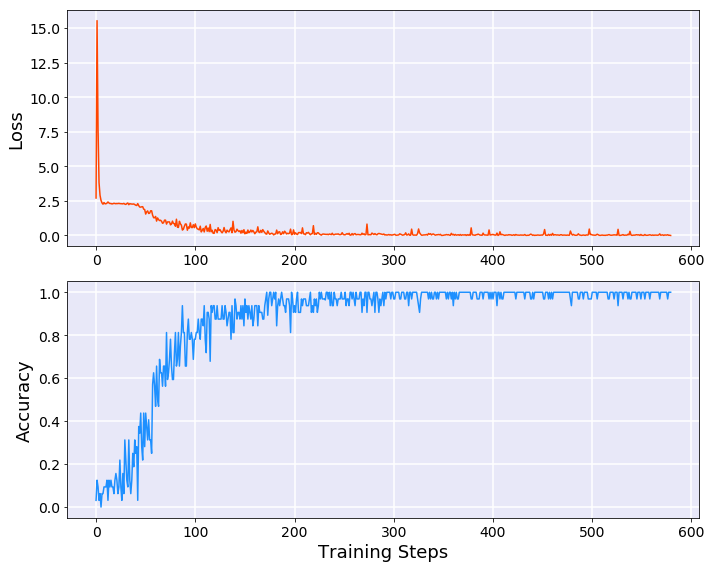
模型训练结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Epoch:0,Batch: 0,Loss:2.70293,Acc:0.06250 Epoch:0,Batch: 30,Loss:2.30669,Acc:0.18750 Epoch:1,Batch: 0,Loss:2.17180,Acc:0.15625 Epoch:1,Batch: 30,Loss:1.20216,Acc:0.53125 Epoch:2,Batch: 0,Loss:0.83113,Acc:0.75000 Epoch:2,Batch: 30,Loss:0.42846,Acc:0.78125 Epoch:3,Batch: 0,Loss:0.17984,Acc:0.96875 Epoch:3,Batch: 30,Loss:0.24534,Acc:0.90625 Epoch:4,Batch: 0,Loss:0.23818,Acc:0.93750 Epoch:4,Batch: 30,Loss:0.28972,Acc:0.84375 Epoch:5,Batch: 0,Loss:0.07945,Acc:0.96875 Epoch:5,Batch: 30,Loss:0.07204,Acc:0.96875 Epoch:6,Batch: 0,Loss:0.08238,Acc:0.96875 Epoch:6,Batch: 30,Loss:0.09043,Acc:0.96875 Epoch:7,Batch: 0,Loss:0.06805,Acc:0.96875 Epoch:7,Batch: 30,Loss:0.02860,Acc:1.00000 Epoch:8,Batch: 0,Loss:0.09906,Acc:0.96875 Epoch:8,Batch: 30,Loss:0.26927,Acc:0.96875 Epoch:9,Batch: 0,Loss:0.02094,Acc:1.00000 Epoch:9,Batch: 30,Loss:0.04960,Acc:0.96875
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 fig = plt.figure(figsize=[10 , 8 ]) ax1 = fig.add_subplot(211 , facecolor="#E8E8F8" ) ax1.set_ylabel("Loss" , fontsize=18 ) plt.tick_params(labelsize=14 ) ax1.plot(range (len (loss_arr)), loss_arr, color="orangered" ) ax1.grid(linewidth=1.5 , color="white" ) ax2 = fig.add_subplot(212 , facecolor="#E8E8F8" ) ax2.set_xlabel("Training Steps" , fontsize=18 ) ax2.set_ylabel("Accuracy" , fontsize=18 ) plt.tick_params(labelsize=14 ) ax2.plot(range (len (acc_arr)), acc_arr, color="dodgerblue" ) ax2.grid(linewidth=1.5 , color="white" ) fig.tight_layout() plt.show() plt.close()
3.4. 模型评估
1 2 3 4 5 6 7 8 9 10 11 12 13 14 model.eval () test_costs, test_accs = [], [] for batch_id, data in enumerate (test_loader()): x_data, y_data = data y_data = y_data[:, np.newaxis] y_pred = model(x_data) acc = M.accuracy(y_pred, y_data) loss = F.cross_entropy(y_pred, y_data) test_accs.append(acc.item()) test_costs.append(loss.item()) test_loss = np.mean(test_costs) test_acc = np.mean(test_accs) print ("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
模型评估结果如下:
1 Eval Loss:0.10308,Acc:0.96429
3.5. 模型预测
1 2 3 4 truth_lab = random.randint(0 , 9 ) infer_path = INFER_PATH + '/infer_%d.JPG' % truth_lab infer_img = data_mapper(infer_path, show=True ) infer_img = infer_img[np.newaxis, :, :, :]
1 2 3 4 5 6 7 8 model.eval () model.set_state_dict( paddle.load(MODEL_PATH) ) result = model(infer_img) infer_lab = np.argmax(result) print ("真实标签:%d,预测结果:%d" % (truth_lab, infer_lab))
模型预测结果如下:
写在最后