【LeNet5】简单车牌识别
1. 项目准备
1.1. 问题导入
本次实践是一个多分类任务,需要将照片中的每个字符分别进行识别,我们将借助CV2模块完成对车牌图像逐字符划分,然后训练卷积神经网络模型LeNet5完成对车牌的识别。
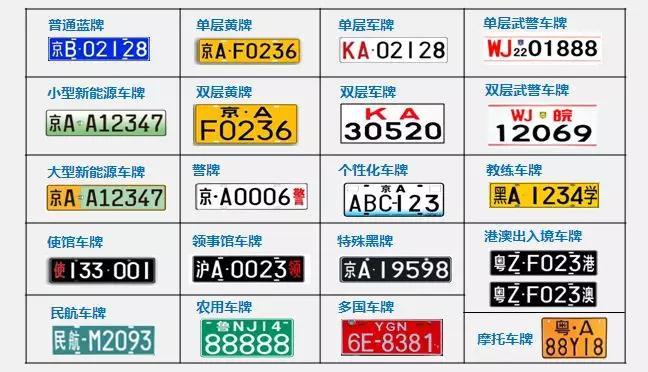
1.2. 数据集简介
实验数据集中有65个文件夹,包含数字 (0-9)、大写字母 (A-Z) 以及各省简称,每个文件夹存放一类图片,所有的图片均为20 * 20像素的灰度图像。

这是数据集的下载链接:车牌识别数据集 - AI Studio
2. LeNet5模型
2.1. 卷积神经网络
本实验使用的模型属于卷积神经网络模型(Convolutional Neural Network,CNN)。一个卷积神经网络通常包括输入层、输出层和多个隐藏层,而隐藏层通常包括卷积层、池化层和全连接层等。
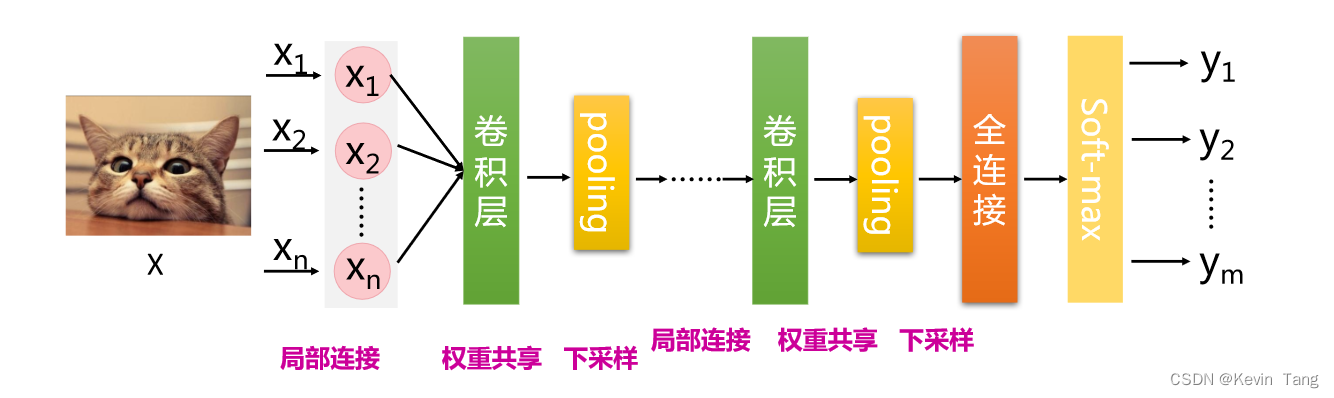
在卷积运算和池化运算中,如果输入维度为,卷积核或池化核的大小为,运算步长为,填充长度为,那么输出维度为。并且在卷积运算中,卷积核的数量与输出通道数相等。
2.2. 模型介绍
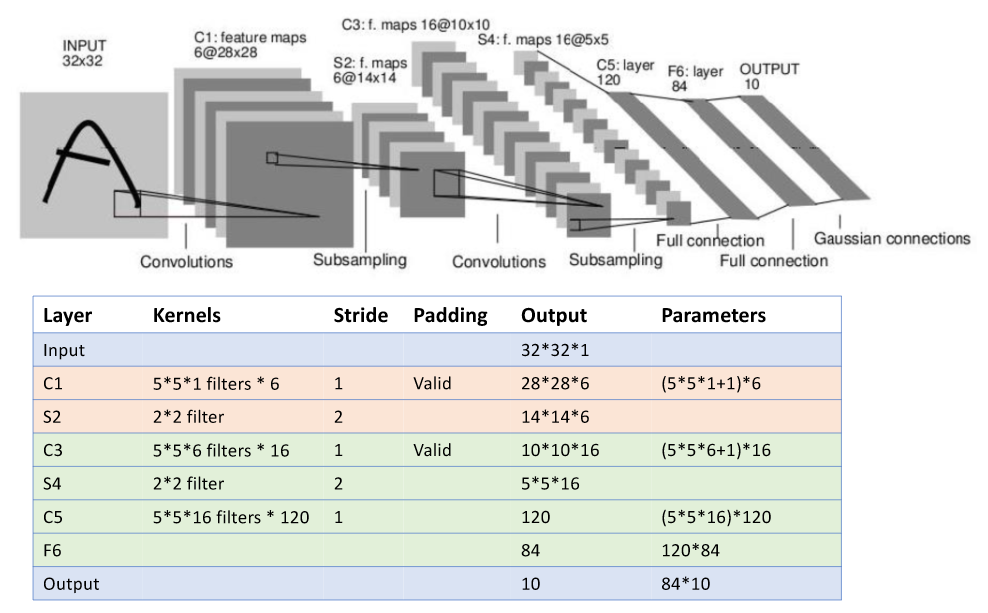
LeNet-5是Yann LeCun(1998)在论文中提出来的,是一种用于手写体字符识别的、结构简单、非常高效的卷积神经网络。LeNet-5大体上由提取特征的三个卷积层和两个分类的全连接层组成,在卷积层之间均插入了最大池化层来缩小特征图,以便于后面的网络层提取更大尺度的特征,并且卷积层和全连接层均采用Sigmoid激活函数(现常用ReLU作为激活函数),其网络结构如下图所示。
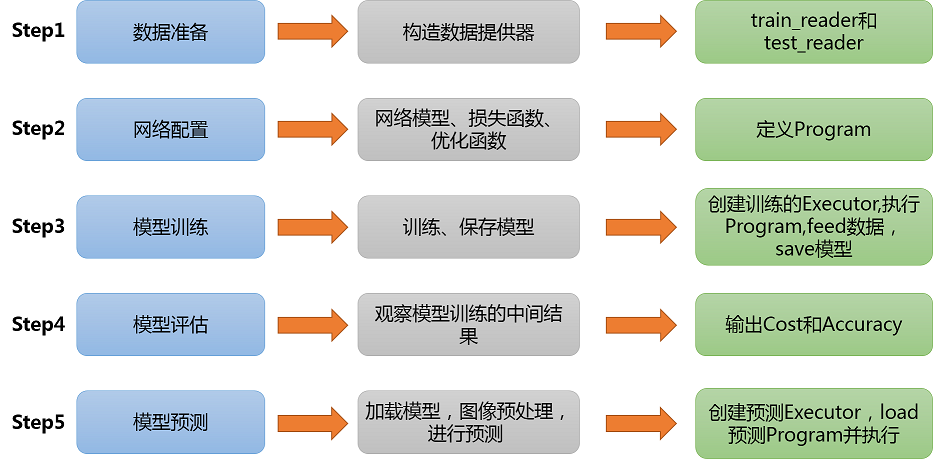
3. 实验步骤
3.0. 前期准备
- 导入模块
注意:本案例仅适用于
PaddlePaddle 2.0+版本
1 | import os |
- 设置超参数
1 | BATCH_SIZE = 128 # 每批次的样本数 |
3.1. 数据准备
- 解压数据集
由于数据集中的数据是以压缩包的形式存放的,因此我们需要先解压数据压缩包。
1 | if not os.path.isdir(DATA_PATH): |
- 划分数据集
我们需要按1:9比例划分测试集和训练集,分别生成两个包含数据路径和标签映射关系的列表。
1 | train_list, test_list = [], [] # 存放数据的路径及标签的映射关系 |
- 数据预处理
我们需要先定义一个数据集类,接着对数据集图像进行缩放和归一化处理。
1 | class MyDataset(Dataset): |
1 | transform = T.Compose([ |
- 定义数据提供器
我们需要分别构建用于训练和测试的数据提供器,其中训练数据提供器是乱序、按批次提供数据的。
1 | train_loader = DataLoader(train_dataset, # 训练数据集 |
3.2. 网络配置
1 | class LeNet5(nn.Layer): |
- 模型实例化
1 | model = LeNet5(in_channels=1, n_classes=char_num) |
3.3. 模型训练
1 | model.train() # 开启训练模式 |
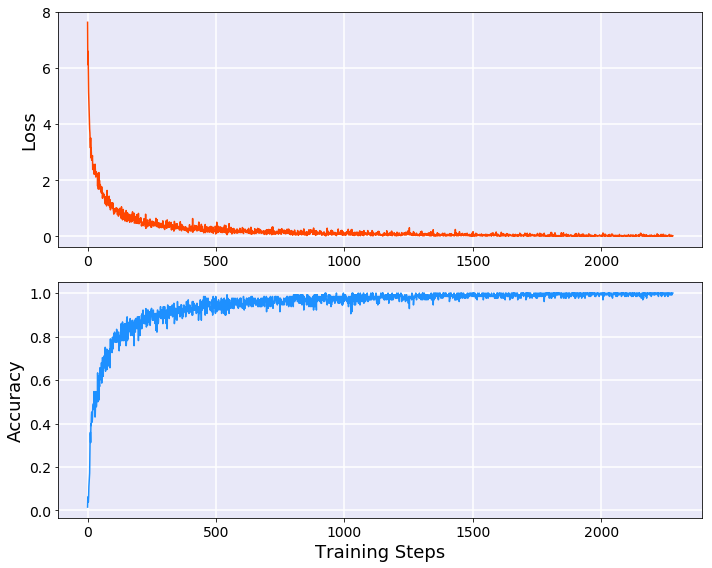
模型训练结果如下:
1 | Epoch:0,Batch:100,Loss:0.93938,Acc:0.77344 |
- 可视化训练过程
1 | fig = plt.figure(figsize=[10, 8]) |
3.4. 模型评估
1 | model.eval() # 开启评估模式 |
模型评估结果如下:
1 | Eval Loss:0.16533,Acc:0.96663 |
3.5. 模型预测
- 预测图片预处理
由于车牌图片是由多个字符构成的RGB模式的图片,因此在进行预测之前需要将车牌图片转化为灰度图并按字符划分子图像,以便于模型逐字符进行预测。
1 | def load_image(path): # 图像整体预处理 |
1 | name_dict = match_labels(label_dict) # 获取转换标签的字典 |

- 载入模型并开始预测
1 | model.eval() # 开启评估模式 |
模型预测结果如下:
1 | 该车牌的预测结果为: 苏A•UP678 |
写在最后
- 如果您发现项目存在问题,或者如果您有更好的建议,欢迎在下方评论区中留言讨论~
- 这是本项目的链接:实验项目 - AI Studio,点击
fork可直接在AI Studio运行~- 这是我的个人主页:个人主页 - AI Studio,来AI Studio互粉吧,等你哦~
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 倾珞珈蓝!
相关推荐





评论
ValineTwikoo


