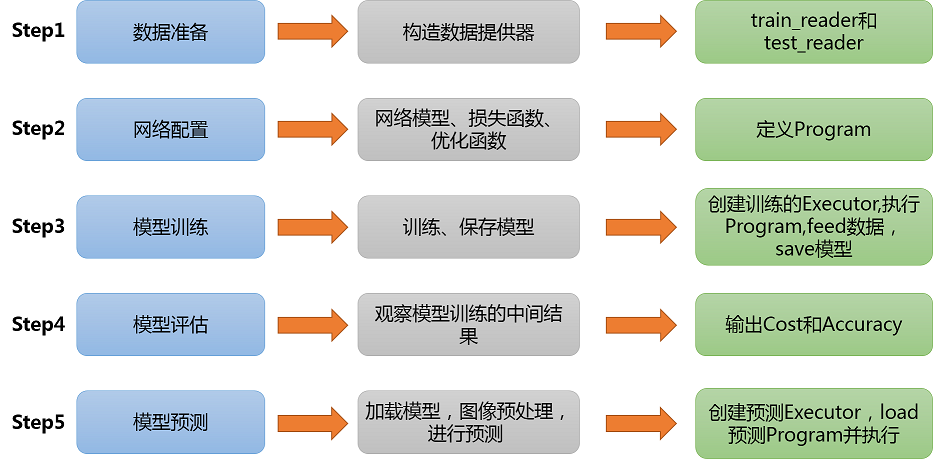
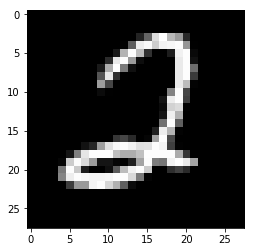1. 项目准备
1.1. 问题导入
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题。现有10类若干张手写数字图片,请训练多层感知机(MLP)模型预测手写数字图片:
1.2. 数据集简介
本实验使用的是PaddlePaddle提供的mnist数据集(paddle.dataset.mnist),它包含60000个训练集和10000测试数据集,分为图片和标签,图片是 28 * 28 的像素矩阵,标签为0~9共10个数字:
2. 实验步骤
2.0. 前期准备
注意:本案例仅适用于PaddlePaddle 2.0+版本
1 2 3 4 5 6 7 8 9 10 11 12 13 import numpy as npfrom PIL import Imagefrom random import randintfrom matplotlib import pyplot as pltimport paddlefrom paddle import nnfrom paddle import metric as Mfrom paddle.io import DataLoaderfrom paddle.nn import functional as Ffrom paddle.optimizer import Adamfrom paddle.vision.datasets import MNISTfrom paddle.vision.transforms import Compose, Normalize
1 2 3 4 5 6 7 BATCH_SIZE = 128 CLASS_DIM = 10 EPOCHS = 4 LOG_GAP = 200 INIT_LR = 2e-4 DATA_PATH = "./data" MODEL_PATH = "MLP.pdparams"
2.1. 数据准备
1 2 3 4 5 transform = Compose([ Normalize(mean=[127.5 ], std=[127.5 ], data_format='CHW' ) ]) train_dataset = MNIST(mode='train' , transform=transform) test_dataset = MNIST(mode='test' , transform=transform)
batch_size:每批次读取样本数。例如batch_size=64表示每批次读取64个样本。shuffle:是否打乱样本。例如shuffle=True表示在取数据时打乱样本顺序,以减少过拟合发生的可能。drop_last:是否丢弃不完整的批次样本。例如drop_last=True表示丢弃因数据集样本数不能被batch_size整除而产生的最后一个不完整的batch样本。num_workers:加载数据的子进程个数。num_workers的值设为大于0时,即开启多进程方式异步加载数据,可提升数据读取速度。
1 2 3 4 5 6 7 8 9 10 11 train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, num_workers=1 , shuffle=True , drop_last=True ) test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, num_workers=1 , shuffle=False , drop_last=True )
2.2. 模型配置
定义多层感知机
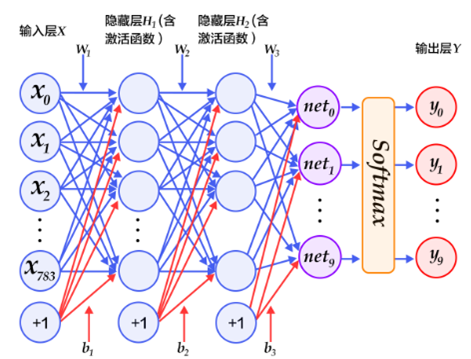
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class MLP (nn.Layer): ''' Multi-Layer Perceptron (MLP) ''' def __init__ (self, n_classes=10 ): super (MLP, self).__init__() self.model = nn.Sequential( nn.Flatten(1 , -1 ), nn.Linear(28 *28 , 1024 ), nn.ReLU(), nn.Dropout(0.25 ), nn.Linear(1024 , n_classes) ) def forward (self, x ): return self.model(x)
1 model = MLP(n_classes=CLASS_DIM)
2.3. 模型训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 model.train() opt = Adam(learning_rate=INIT_LR, parameters=model.parameters()) loss_arr, acc_arr = [], [] for ep in range (EPOCHS): for batch_id, data in enumerate (train_loader()): x_data, y_data = data y_pred = model(x_data) acc = M.accuracy(y_pred, y_data) loss = F.cross_entropy(y_pred, y_data) if batch_id % LOG_GAP == 0 : print ("Epoch:%d,Batch:%3d,Loss:%.5f,Acc:%.5f" \ % (ep, batch_id, loss, acc)) acc_arr.append(acc.item()) loss_arr.append(loss.item()) opt.clear_grad() loss.backward() opt.step() paddle.save(model.state_dict(), MODEL_PATH)
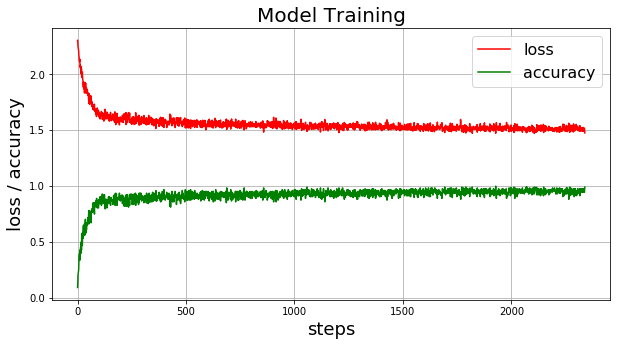
模型训练的结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 Epoch:0,Batch: 0,Loss:2.63496,Acc:0.14062 Epoch:0,Batch:200,Loss:0.42945,Acc:0.86719 Epoch:0,Batch:400,Loss:0.19543,Acc:0.96094 Epoch:1,Batch: 0,Loss:0.18954,Acc:0.96094 Epoch:1,Batch:200,Loss:0.18587,Acc:0.95312 Epoch:1,Batch:400,Loss:0.18084,Acc:0.96094 Epoch:2,Batch: 0,Loss:0.12029,Acc:0.97656 Epoch:2,Batch:200,Loss:0.18207,Acc:0.95312 Epoch:2,Batch:400,Loss:0.18604,Acc:0.92188 Epoch:3,Batch: 0,Loss:0.14635,Acc:0.97656 Epoch:3,Batch:200,Loss:0.13389,Acc:0.95312 Epoch:3,Batch:400,Loss:0.06493,Acc:0.99219
1 2 3 4 5 6 7 8 9 plt.figure(figsize=[10 , 5 ]) plt.title("Model Training" , fontsize=20 ) plt.xlabel("steps" , fontsize=18 ) plt.ylabel("loss / accuracy" , fontsize=18 ) plt.plot(range (len (loss_arr)), loss_arr, color="r" , label="loss" ) plt.plot(range (len (acc_arr)), acc_arr, color="g" , label="accuracy" ) plt.legend(fontsize=16 ) plt.grid() plt.show()
2.4. 模型评估
1 2 3 4 5 6 7 8 9 10 11 12 13 model.eval () test_costs, test_accs = [], [] for batch_id, data in enumerate (test_loader()): x_data, y_data = data y_pred = model(x_data) acc = M.accuracy(y_pred, y_data) loss = F.cross_entropy(y_pred, y_data) test_accs.append(acc.item()) test_costs.append(loss.item()) test_loss = np.mean(test_costs) test_acc = np.mean(test_accs) print ("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
模型评估的结果如下:
1 Eval Loss:0.09750,Acc:0.97296
2.5. 模型预测
这是预测数据集的下载链接:手写数字预测数据集 - AI Studio ,它包含从0到9的10张数字图片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def load_image (path ): img = Image.open (path) plt.imshow(img) plt.show() img = img.convert("L" ) img = img.resize((28 , 28 ), Image.ANTIALIAS) img = np.array(img).reshape(1 , 1 , 28 , 28 )\ .astype(np.float32) img = img / 255.0 * 2.0 - 1.0 img = paddle.to_tensor(img) return img truth_lab = randint(0 , 9 ) img_path = DATA_PATH + "/infer_%d.png" infer_img = load_image(img_path % truth_lab)
随机选取的预测图片如下:
1 2 3 4 5 6 7 model.eval () model.set_state_dict( paddle.load(MODEL_PATH) ) result = model(infer_img) infer_lab = np.argmax(result) print ("真实标签:%d,预测结果:%d" % (truth_lab, infer_lab))
模型预测的结果如下:
写在最后