1. 项目准备
1.1. 问题导入
KMeans聚类算法是一种非层次聚类算法,在最小误差的基础上将数据划分了特定的类,类间利用距离作为相似度指标,两个向量之间的距离越小,其相似度就越高。已知中国部分二级城市的经纬度,要求利用经纬度坐标进行KMeans聚类分析。
1.2. 数据集简介
本案例的数据集包含4列351行数据,每行数据包含一个城市,其中前两列为城市所在省和市,最后两列为城市的经纬度。
这是数据集的下载链接:中国主要城市经纬度数据集 - AI Studio
2. K-Means算法
2.1. 算法特点
K-Means聚类算法是一种基于向量距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为类簇是由距离靠近的对象组成的,因此它把得到紧凑且独立的类簇作为聚类的最终目标。
2.2. 算法流程
K-Means算法的基础是最小误差平方和准则,K-Means算法具体流程如下:
2.3. 算法缺陷
(1)种子点的个数要事先确定,但是我们一般很难估计它的个数。
2.4. 算法改进
K-Means++算法是改进后的K-Means算法,具体算法流程如下:
3. 实验步骤
3.1. 前期准备
1 2 3 4 5 import pandas as pdimport numpy as npfrom matplotlib import pyplot as pltfrom sklearn.cluster import KMeansfrom sklearn.metrics import silhouette_score, silhouette_samples
1 2 3 4 N_CLUSTERS = 7 MARKERS = ['*' , 'v' , '+' , '^' , 's' , 'x' , 'o' ] COLORS = ['r' , 'g' , 'm' , 'c' , 'y' , 'b' , 'orange' ] DATA_PATH = './data/China_cities.csv'
3.2. 读入数据
1 2 df = pd.read_csv(DATA_PATH) print (df.head())
前5行数据的输出结果:
1 2 3 4 5 6 省级行政区 城市 北纬 东经 0 北京 北京市 39.904690 116.40717 1 天津 天津市 39.085100 117.19937 2 上海 上海市 31.230370 121.47370 3 重庆 重庆市 29.564710 106.55073 4 香港特别行政区 九龙 22.327115 114.17495
3.3. 数据预处理
我们需要将各城市的经纬度数据单独提取出来。
1 2 3 x = df.drop('省级行政区' , axis=1 ) x = x.drop("城市" , axis=1 ) x_np = np.array(x)
3.4. 模型构建与训练
本项目使用K-Means聚类算法 来对城市的经纬度特征进行聚类。
1 2 model = KMeans(N_CLUSTERS) model.fit(x)
计算轮廓系数 [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ] 1 1 1 K K K i i i S i = B i − A i m a x ( A i , B i ) S_i = \frac{B_i-A_i}{max(A_i, B_i)} S i = ma x ( A i , B i ) B i − A i A i A_i A i i i i i i i B i B_i B i i i i i i i
1 2 3 4 labels = model.labels_ print (silhouette_score(x, labels))
模型的轮廓系数如下:
3.5. 导出类簇信息
1 print (model.cluster_centers_)
最终的类簇中心如下:
1 2 3 4 5 6 7 [[ 36.30742841 105.21526409] [ 27.85671809 102.12971362] [ 41.34384438 84.09634 ] [ 44.01411423 124.90852352] [ 24.3572954 111.87362376] [ 29.06106948 118.51486687] [ 36.22217001 115.34626425]]
1 2 3 for i in range (N_CLUSTERS): print (f" CLUSTER-{i+1 } " .center(60 , '=' )) print (df[labels == i])
各类簇包含的元素如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 ======================== CLUSTER-1 ========================= 省级行政区 城市 北纬 东经 2 上海 上海市 31.230370 121.473700 10 台湾省 台中市 24.138620 120.679510 11 台湾省 台北市 25.037798 121.565170 .. ... ... ... ... ======================== CLUSTER-2 ========================= 省级行政区 城市 北纬 东经 3 重庆 重庆市 29.56471 106.55073 221 四川省 成都市 30.57020 104.06476 222 四川省 自贡市 29.33920 104.77844 .. ... ... ... ... ======================== CLUSTER-3 ========================= 省级行政区 城市 北纬 东经 0 北京 北京市 39.90469 116.40717 1 天津 天津市 39.08510 117.19937 17 河北省 石家庄市 38.04276 114.51430 .. ... ... ... ... ======================== CLUSTER-4 ========================= 省级行政区 城市 北纬 东经 336 西藏自治区 阿里地区 30.40051 81.14540 337 新疆维吾尔自治区 乌鲁木齐市 43.82663 87.61688 338 新疆维吾尔自治区 克拉玛依市 45.57999 84.88927 .. ... ... ... ... ======================== CLUSTER-5 ========================= 省级行政区 城市 北纬 东经 4 香港特别行政区 九龙 22.327115 114.174950 5 香港特别行政区 新界 22.341766 114.202408 6 香港特别行政区 香港岛 22.266416 114.177314 .. ... ... ... ... ======================== CLUSTER-6 ========================= 省级行政区 城市 北纬 东经 73 辽宁省 沈阳市 41.677180 123.463100 74 辽宁省 大连市 38.913690 121.614760 75 辽宁省 鞍山市 41.107770 122.994600 .. ... ... ... ... ======================== CLUSTER-7 ========================= 省级行政区 城市 北纬 东经 267 陕西省 西安市 34.34127 108.93984 268 陕西省 铜川市 34.89673 108.94515 269 陕西省 宝鸡市 34.36194 107.23732 .. ... ... ... ...
3.6. 类簇可视化
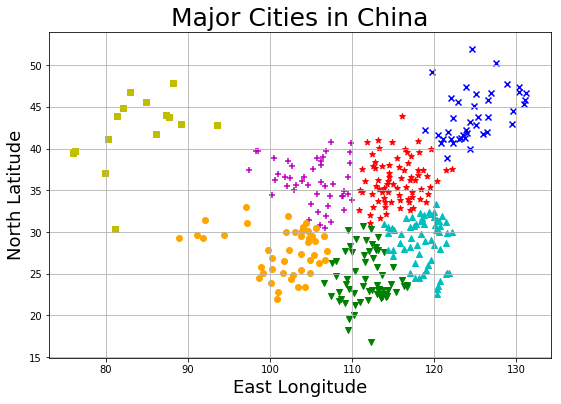
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 plt.figure(figsize=(9 , 6 )) plt.title("Major Cities in China" , fontsize=22 ) plt.xlabel('East Longitude' , fontsize=18 ) plt.ylabel('North Latitude' , fontsize=18 ) for i in range (N_CLUSTERS): members = labels == i plt.scatter( x_np[members, 1 ], x_np[members, 0 ], marker = MARKERS[i], c = COLORS[i] ) plt.grid() plt.show()
基于经纬度的城市聚类结果:
写在最后